


最近(其實也一段時間)我都在研究TensorFlow和機器學習(Machine Learning / ML)可以怎樣用;我買了些網上課、看Youtube和看書;但是在學習的過程中,覺得這Tensorflow東西真的很難上手。
這個系列的出現,目標是透過補完一些知識,降低這門學問的門檻,讓大家進入TensorFlow的世界。
從官網看Tensorflow
在網站Banner,你會看到這些關鍵字:
- 機器學習、模型、部署、機器學習解決方案
Scroll下一點,看到功能介紹部分:

你會看到另一些關鍵字:準備資料、建構模型、部署模型、導入機器運作 (MLOp)
其實從官網中這些關鍵字,已經說明了Tensorflow大致的功用; 不過,如果你對機器學習沒有任何理解的話,以上的關鍵字例如機器學習、準備資料、訓練模型等,對你來說,應該會“一頭霧水”吧。
另外,你可能閱讀時,會找到這段Tensorflow的 Hello world 程序:
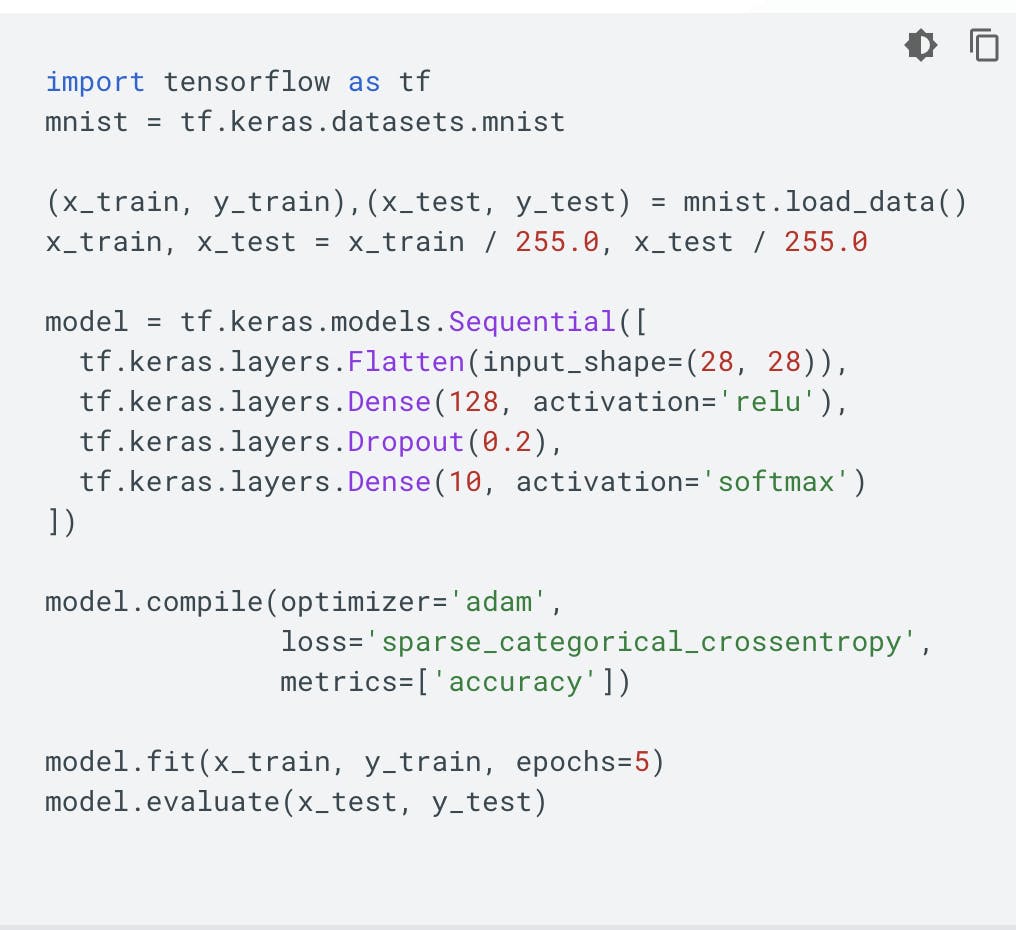
就算你能跑動這代碼,但你未必知道發生什麼事情; 如果要你把代碼運用在你的項目中,基本上不可能了。
所以,Tensorflow官網主要是給已經對機器學習有一定基礎的人去看;如果不太理解的話就去學的話,應該會事倍功半。所以文章之後的內容,會說明一下什麼事機器學習。
ML是什麼
機器學習 (Machine Learning / ML) 就是字面的解釋,機器自行學習。那不就是 ”多拉A夢、3PO" ?? :

如果是普遍的定義,其實真的是這樣;而編程/學術的理解是這樣:

機器學習的概念就是程序的邏輯/法則( Logic / Rule)不是透過開發人員編寫,而是利用數據,通過不斷的學習,把相關邏輯規則演變出來。
對於開發者來說,這是一個很有效的解決問題的方案,我們只需要足夠數據,就不用編寫代碼來解決問題,例如文字辨識(OCR),文字轉語音等。
雖然有機器學習的方案,但這不代表所有問題需要利用ML來解決。
什麼是模型?
當我們閱讀有關機器學習或關於AI的文章,應該常常看到模型(Model)這個字眼;簡單來說,Model是指把結果計算出來的程序,例如:
圖片分類器:根據輸入圖片,估算他是什麼東西;
走勢預測器:跟進輸入數值(例如樓宇面積),估算未來幾年的樓價。
而Model另一個重點,就是包含一些參數,而隨著這些參數的變化,我們可以獲得不同的預測結果;另外這些參數會隨著“訓練”不斷調整,另結果變得更好。
而我們常常聽到的預訓練模型 (Pre-train Model)就是已經訓練好的模型,例如現在很流行的ChatGPT,就是運用了預先訓練好的模型。
所以,但你看Tensorflow的文檔或書本,就會常常看到這幾個東西:數據集(Data set)、模型(Mode)、訓練(Train)。
ML怎樣訓練模型
機器學習的其中一個核心,就訓練模型;而訓練模型的重點在於透過數據不斷地改善模型的準確性或是說表現。大致流程如下:
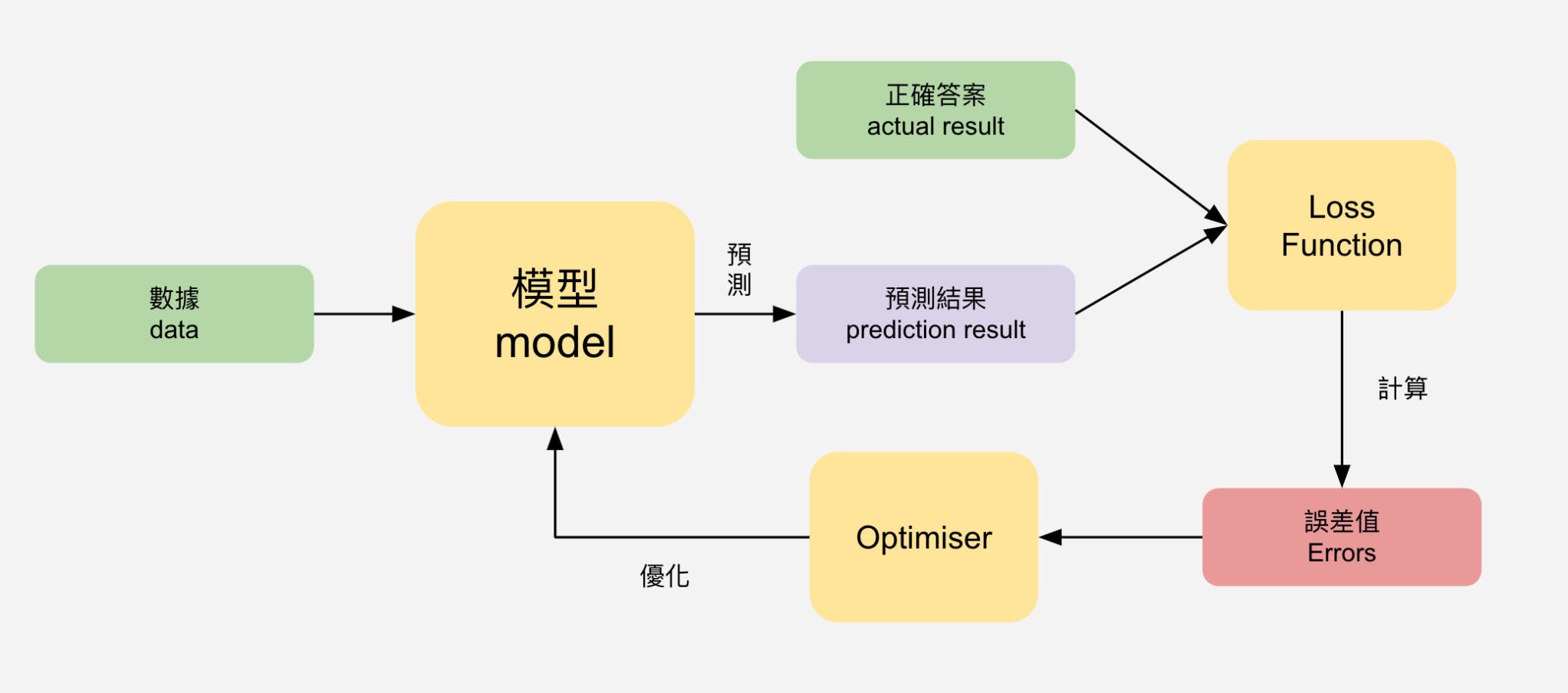
所以製作Machine Learning,需要製作2個東西,就是Model 和 Loss Function; Model在上一段落中解說了,這裡就不重複了。
而Loss Function,或稱為Errors Function 或 Cost Function,是用於計算預測結果(prediction result)和正確結果(Actual Result)的差異,也即是Error (錯誤值)。
獲取error資訊後,會反饋error到一個叫Optimiser的東西,從而調整Model的參數,令Error減少。
Tensorflow在訓練模型這個環節中,提供了不同的loss function和optimiser,也提供了工具(utility)給開發者製作Model。
ML製作流程
上一節說的製造及訓練模型,其實是開發ML應用/解決方案其中一環,在實際項目上,還需要其他部分,以下就是整個流程:
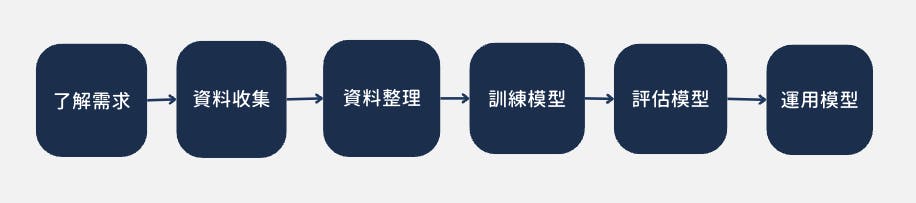
了解需求:流程的第一步,就是要考慮ML用在那些地方和怎樣做。
資料收集:由於機器學習要數據才能把模型訓練成功,這一步需要分析需要那些數據和怎樣獲取它們。
資料整理:這一步需要進行篩選數據篩選、切割給訓練和評估使用、歸一(Normalization)等工作,讓下一步“訓練模型”能順利進行。
訓練模型:利用收集的數據進行訓練。
運用模型:運用匯出的模型放到不同地方,例如手機應用程序,或網站,讓AI進行預測,例如辨認手寫文字。
以上不同的部分,其實Tensorflow都有提供不少工具,例如:
資料收集:下載不同的數據集(Data set)
運用模型:提供 Tensorflow Lite,Tensorflow.js 等給不同Device使用。
解釋TF Helloworld 代碼
最後,透過解釋這段Hello World代碼,讓大家了解 Tensorflow和ML的關係

這裡同時載入和整理數據,
mnist.load_data就是把手寫數字(MNIST)的數據下載,並同時分配給訓練和評估使用;定義模型結構;
配置模型:這裡能設定模型使用的優化方法(optimizer)和計算錯誤(loss)的方法;
訓練模型:
model.fit(...)在這裡就是訓練模型的意思評估模型:
model.evaluate(..)可以計算出模型的準確率
思考問題?
什麼時不應該使用ML (機器學習)?
如過ML是根據數據創造”邏輯“,那麼數據怎樣來,怎樣才夠?
總結
如果大家看了這篇文章,還是不太理解的話,其實也正常的,因為Tensorflow 和機器學習都需要親身體驗(即是寫Code)才能有領悟。
另外,看看以下3個介紹ML的視頻:
最後,大家也可以直接問我的;可透過Facebook和Twitter聯繫我;
另外,請加入我的FB專頁,有新文章發布時,大家就能立即知道了。
Facebook 專頁連結:https://www.facebook.com/kencoder1024
Twitter連結:https://twitter.com/kenlakoo